Siddhant Kharbanda
I am a masters student and graduate student researcher at University of California, Los Angeles (UCLA) working with Prof. Cho-Jui Hsieh on effective Dual Encoder algorithms for Search and Recommendation. I aim at bridging the gap between Extreme Multilabel Classification and Dense Retrieval algorithms. I received my bachelors degree in Computer Science from BITS Pilani, India and pursued my bachelors thesis at Aalto University, Finland, working with Prof. Rohit Babbar.
Previously, I was working as an Applied Scientist in Microsoft's Bing Text Ads team. My time at Microsoft was dedicated to developing scalable multi-lingual dual encoder models and training them over billions of query keyword pairs. More recently, my research focus has switched to exploring multi-lingual supervised fine-tuning of large language models aimed at better Retrieval Augmented Generation (RAG). My goal is to develop efficient multi-lingual conversational search and recommendation solutions to provide users with more accurate summarized search results.
More broadly, I am also interested in multi-modal machine learning and have worked with Prof. Hanspeter Pfister and Dr. Donglai Wei at Harvard University on Video Instance Segmentation.
Email / CV / GitHub / LinkedIn
Timeline
- [Jan 2024] Started working as a Graduate Student Researcher at UCLA.
- [Sep 2023] Started MS CS at UCLA.
- [Jul 2023] Second-authored paper accepted at ICCV'23.
- [Feb 2023] First-authored paper accepted at SIGIR'23.
- [Oct 2022] Joined Microsoft, India as an Applied Scientist in Bing Text Ads team.
- [Sep 2022] First-authored paper accepted at NIPS'22.
- [Mar 2022] First-authored paper accepted at CVPR'22.
- [Aug 2021] Joined Elisa, Finland as an NLP Research Engineer.
- [Jan 2021] Started bachelors thesis at Aalto University, Finland.
- [Aug 2020] Joined Visual Computing Group, Harvard University as an undergrad student researcher

Publications
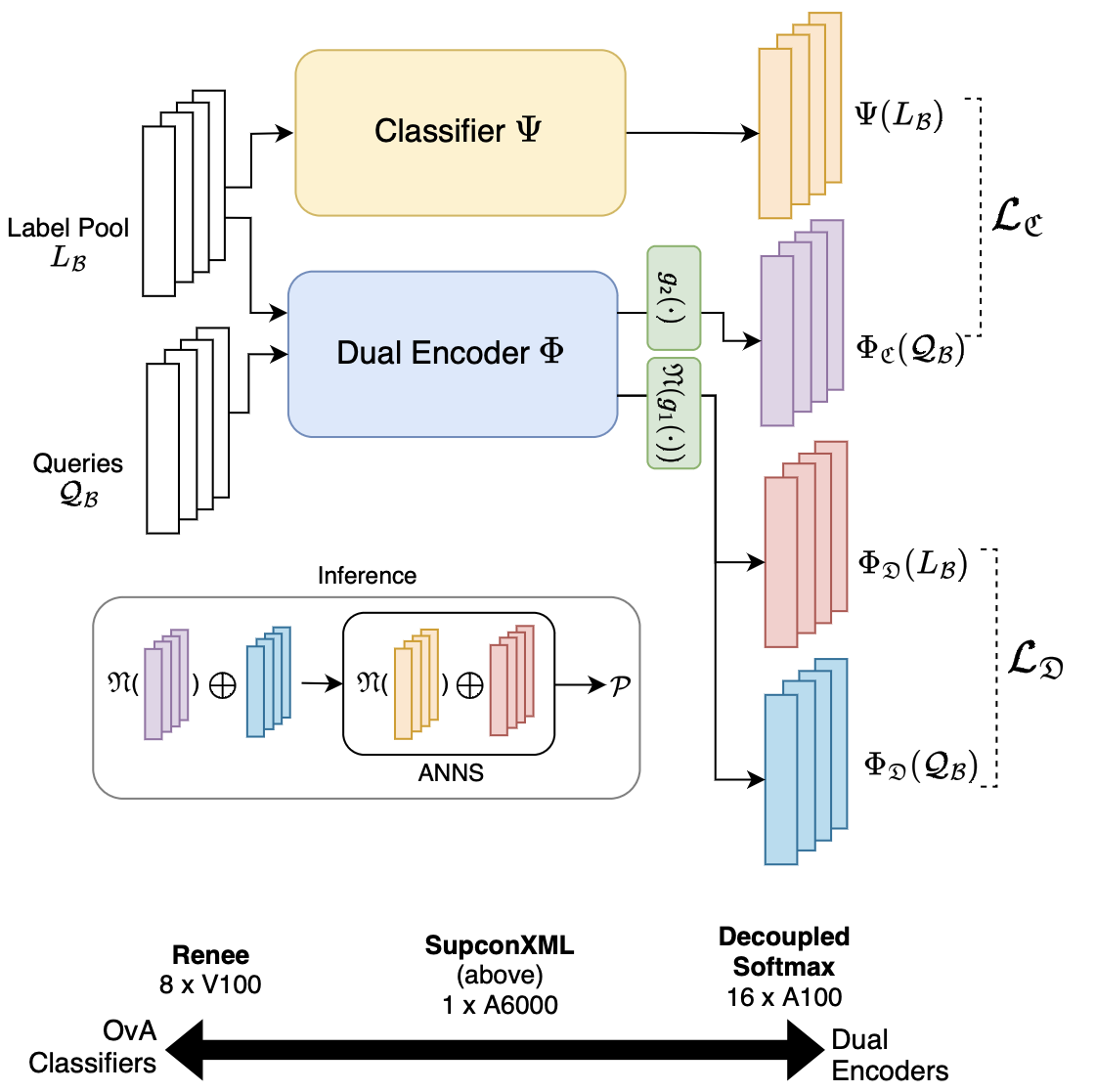
UniDEC: Unified Dual Encoder and Classifier Training for Extreme Multi-label Classification
Preprint, 2024
UniDEC defines a “pick-some-labels” multi-class reduction for multilabel classification over a batch and leverages Supervised Contrastive Learning to train both the dual encoder and classifier in a unified end-to-end fashion, achieving state-of-the-art performance on a single GPU.
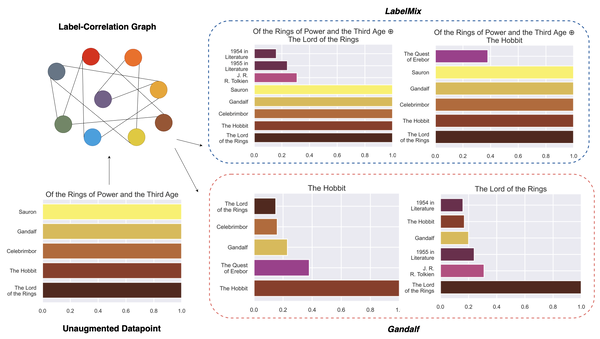
Gandalf: Learning label correlations in Extreme Multi-label Classification via Label Features
Preprint, 2024
We investigate label correlations in output space in the order of millions and develop Gandalf, a novel data augmentation setup, which leverages label correlation graph to create soft-targets to use label-text as train data points.
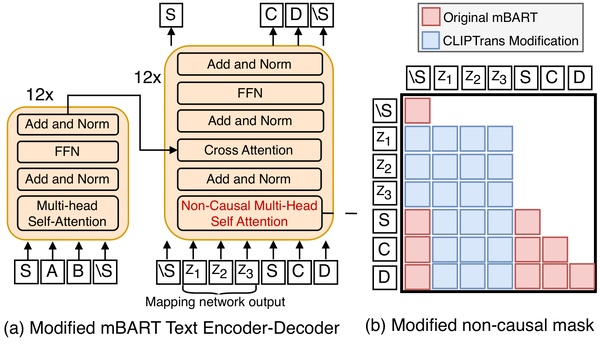
CLIPTrans: Transferring Visual Knowledge with Pre-trained Models for Multimodal Machine Translation
ICCV, 2023
project / code
CLIPTrans presents a novel training algorithm for multi-modal machine translation (MMT) that leverages image-text aligned CLIP embeddings as prefixes to the multi-lingual translations model mBART to further the MMT SOTA set by MIT/Google. We demonstrate improvements using only a fraction of data required for pre-training from scratch, with more prominent improvements witnessed across low-resource languages.
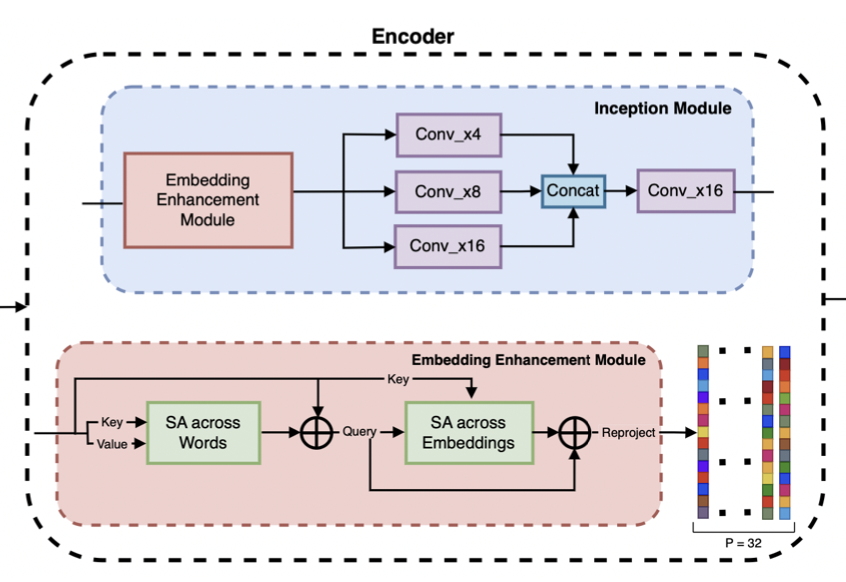
InceptionXML: A Lightweight Framework with Synchronized Negative Sampling for Short Text Extreme Classification
SIGIR, 2023
video / code
We develop lightweight CNN-based encoder, InceptionXML, suitable for short-text queries and a scalable framework, SyncXML, for extreme classification over millions of labels that requires less than 2% FLOPs as compared to BERT-based models and is 3-5x faster for inference. InceptionXML in SyncXML beats the previous SOTA on a multitude of performance and parametric metrics.
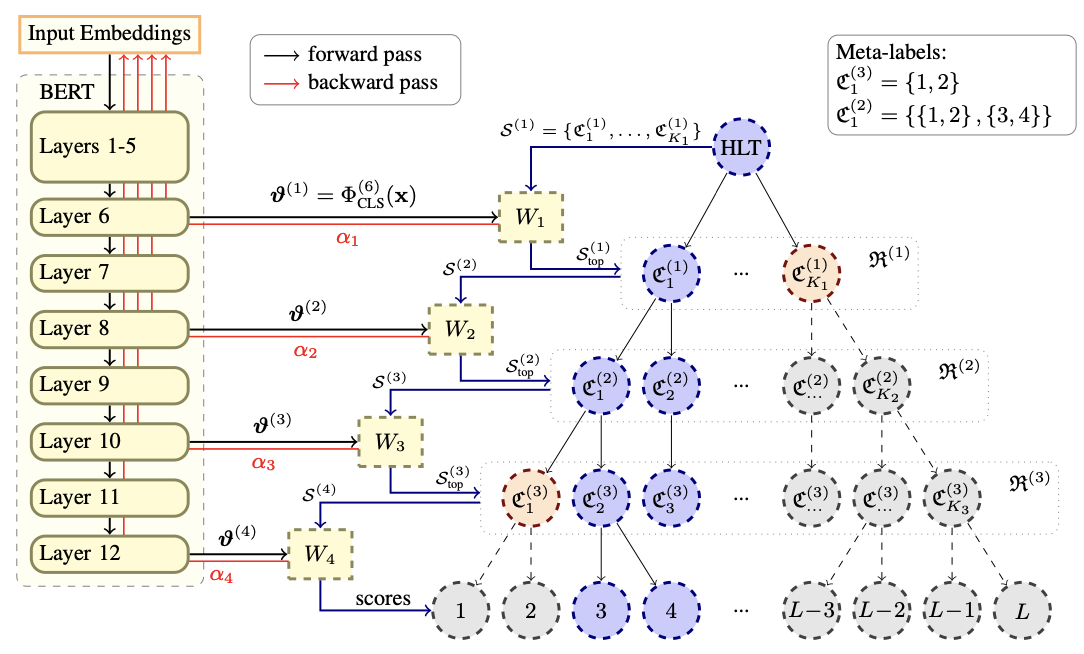
CascadeXML: Transformers for End-to-end Multi-resolution Training in Extreme Classification
NeurIPS, 2022
video / code
CascadeXML is an end-to-end transformer fine-tuning algorithm which aligns the intermediate layers to the multiple resolutions of a hierarchical label tree to perform multi-label classification over millions labels in a beam-search fashion, via multi-resolution dynamic hard negative mining, outperforming Amazon’s PECOS Framework by 4-6% across 5 public benchmarks while cutting GPU requirements and inference time by half.
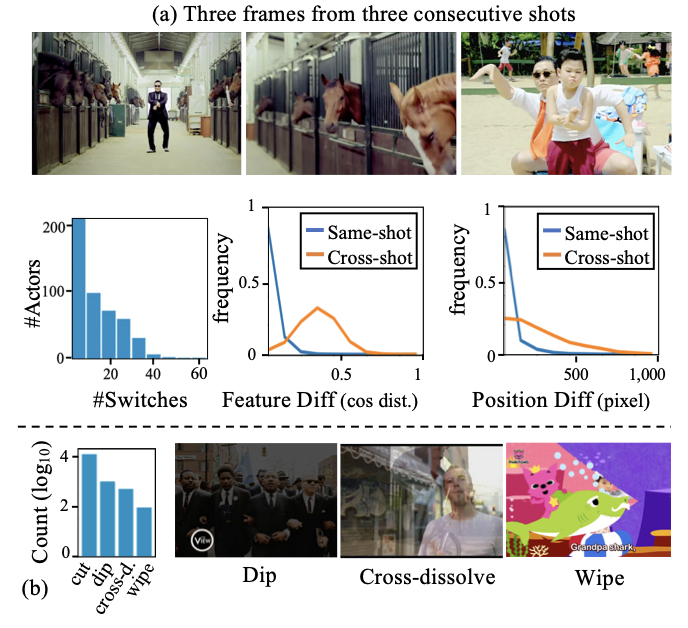
YouMVOS: An Actor-centric Multi-shot Video Object Segmentation Dataset
CVPR, 2022
project / code
We present YouMVOS as the 1st Multi-shot video object segmentation dataset for long-scene, cross-shot videos and a Video Instance Segmentation (VIS) model which equips the Hybrid Task Cascade (HTC) architecture with pose and face re-identification modules and, achieves 39.3 mAP on YoutubeVIS’19 using a ResNet-50 backbone.